|
1.爬虫和抓取 搜索引擎派出一个能够在网上发现新网页并抓文件的程序,这个程序通常称之为蜘蛛。搜索引擎从已知的数据库出发,就像正常用户的浏览器一样访问这些网页并抓取文件。 2.索引 蜘蛛抓取的页面文件分解、分析,并以巨大表格的形式存入数据库。 3.搜索词处理 在搜索引擎界面输入关键词,单击“搜索”按钮后,搜索引擎程序即对搜索词进行处理,如中文分词处理,判断是否需要整合类目属性信息,判断是否有拼写错误或错别字等情况。搜索词的处理必须十分快速。 4.排序
对搜索词处理后,搜索引擎程序从索引数据库中找出所有包含搜索词的商品,并且根据排名算法计算出哪些网页应该排在前面,然后按照一定格式返回到“搜索”页面。 搜索相关性原理 1、仅标题部分、广告词、类目建索引、用户搜索到的商品需在标题中出现 2、按字切词、索引,保证查全率 3、精确匹配与模糊匹配 4、相关性权重涉及因素:词频、词间距、是否有广告词 5、标题中应含有品牌、型号、类别、关键属性、功能、别称等 6、搜索词与类目关系:商品相关性与商品分类、用户点击有关
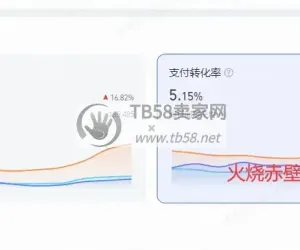
7、业务原则和用户搜索原则;例如:用户搜索:“篮球” 搜索排序原理 1、相关性排序计算:标题、类目、属性、销量、评论数、价格等因素的综合 2、交易性排序计算:销量、价格 3、评论数排序计算:好评度、评论数计算 4、时效性排序计算:上架时间 5、综合各种相关性与商品的商业属性综合算出的排序分值。 搜索排序筛选 1、销量排序:七日销量,价格权重,好评度 2、价格排序:按照商品的价格进行高低排序 3、好评度排序:好评度、全部评论数综合因素 4、商品上架时间:按照商品上架时间排列 搜索下拉框提示: 数据来源:用户搜索词,搜索日志 排序:按照相关性进行排序
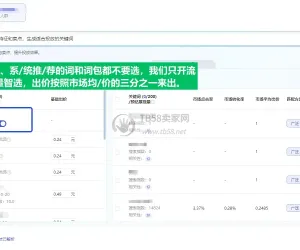
更新日期:每月更新,采销可提供词表
| 





















 微信公众号
微信公众号 官方抖音号
官方抖音号